前言
在《Redis实战》这本书的第六章中,作者介绍了如何使用Redis的ZSET来实现通讯录自动补全(即前缀匹配查询)。这部分内容激发了我的兴趣,于是我借助这个机会抛出问题:如何高效地对100万个UUID进行前缀匹配,并尝试用这篇文章来解答。
数据准备 首先是数据准备工作:生成100万个UUID、将其写入至Redis和MariaDB(后者可作为对比)。顺便一提,Redis和MariaDB均在笔者电脑上通过Docker部署,版本分别为Redis 6.0和MariaDB 10.4。
1 2 3 4 5 6 7 $ $ for i in {0..999999}; do uuidgen; done > uuids_1m.txt$ du uuids_1m.txt -h$ head -n2 uuid_1m.txt
1 2 redis> zcount uuids -inf +inf
1 2 3 4 5 6 # MariaDB表结构,在uuid字段加了索引create table uuids (int primary key auto_increment,char (36 ) not null ,
1 2 3 4 5 6 7 8 9 10 11 12 mariadb> select count (* ) from uuids;+ | count (* ) | + | 1000000 | + > select table_name, data_length, index_length from information_schema.tables where table_name= 'uuids' ;+ | table_name | data_length | index_length | + | uuids | 64569344 | 78397440 | +
可以看到,在插入100万条UUID数据后,MariaDB数据表的大小超过了60MB,索引的大小超过了70MB。同时,数据准备完成后,Redis和MariaDB的内存占用从刚部署时的5M和80M上升至了120M和270M。
Python遍历查询 数据准备完成后,下面要做的就是进行前缀匹配查询。最直接的方式应该是遍历查询了,实现起来也简单,但O(n)的时间复杂实在是让人不敢恭维,代码贴出来权当消遣。
为了更符合前缀匹配查询的定义,我在读取完UUID后还会对数据进行一次排序操作,而这个排序的时间消耗是不会被统计到后续的性能对比中的,这对下一节的二分查询同样适用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 uuids = []def traverse (prefix: str , limit=10 ):0 while start < len (uuids) and not uuids[start].startswith(prefix):1 for i in range (start, min (start + limit, len (uuids))):if not uuids[i].startswith(prefix):break return ans
Python二分查询 遍历查询最大的问题在于其O(n)的时间复杂度。但只要目标数据是有序的,那就到时间复杂度只有O(log n)的二分查询上场的时候了。对于前缀匹配查询来说,查询以abcd开头的字符串,本质上是查询比abcczzzz...大的字符串。而在代码中,我用0xffff这个边界符号来代替前文提到的那一串zzzz....,这对UUID这种不超过ASCII码范围的字符串来说已经足够了。
同时,代码里二分查找的结果(start)是第一个大于要找的字符串的元素的下标,这点需要注意。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def bin_search (prefix: str , limit=10 ):1 ] + chr (ord (prefix[-1 ]) - 1 ) + chr (0xffff )0 , len (uuids) - 1 while left <= right:2 if uuids[mid] == target:1 break elif uuids[mid] < target:1 else :1 else :for i in range (start, min (start + limit, len (uuids))):if not uuids[i].startswith(prefix):break return ans
Redis+ZSET查询 Redis+ZSET查询的原理和二分查询原理的类似。Redis中的ZSET默认会按照元素的分值进行排序,但如果两个元素的分值一致,那就按元素本身排序。换言之,在ZSET里存放多个分值一致的UUID,从中任意取出一段UUID,这些UUID必然是有序的。
而为了进行前缀匹配查询,我们需要在ZSET里插入两个边界元素,用来标示开始和结束。对于前缀abcd来说,这两个边界元素就是abcc0xffff和abcd0xffff,ZSET里这两个边界元素之间的数据就是我们想要查询的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def redis_zset (prefix: str , limit=10 ):str (uuid4())1 ] + chr (ord (prefix[-1 ]) - 1 )chr (0xffff ) + identifierchr (0xffff ) + identifier"uuids" , {start: 0 , end: 0 }) "uuids" , start) + 1 "uuids" , end) - 1 min (si + limit - 1 , ei)"uuids" , si, ei)"uuids" , start, end)0 ] "utf-8" ) for uuid in zr]return [uuid for uuid in ans if chr (0xffff ) not in uuid]
可以看到,查询过程还是很复杂的:要先插入边界元素,再找出两个边界元素的位置,再用边界元素的位置获取查询结果。而且由于过程复杂,这种方法实际的性能表现并不能让人满意,这个之后再分析。
这段代码有很大的隐患:没有考虑多个查询同时执行的情况。更完善的实现请参考《Redis实战》第六章:使用Redis构建应用程序组件
MariaDB+Like查询 最后介绍一种简单粗暴的查询方法:MariaDB+Like查询,一条SQL解决。
1 2 3 4 def mysql_like (prefix: str , limit=10 ):"select uuid from uuids where uuid like %s order by uuid limit %s" '%' , limit))return [uuid for uuid, in cursor.fetchall()]
验证&性能测试 用5678e这个前缀来验证四种查询方法的正确性。
1 2 3 4 5 6 7 8 ['5678e37b-6e7c-4760-89aa-1dc4c2b547c5' , '5678e967-4d5d-4e26-8ed1-bd8819b5b62c' ]'5678e' ): 0.108424 s'5678e37b-6e7c-4760-89aa-1dc4c2b547c5' , '5678e967-4d5d-4e26-8ed1-bd8819b5b62c' ]'5678e' ): 0.000020 s'5678e37b-6e7c-4760-89aa-1dc4c2b547c5' , '5678e967-4d5d-4e26-8ed1-bd8819b5b62c' ]'5678e' ): 0.002244 s'5678e37b-6e7c-4760-89aa-1dc4c2b547c5' , '5678e967-4d5d-4e26-8ed1-bd8819b5b62c' ]'5678e' ): 0.000773 s
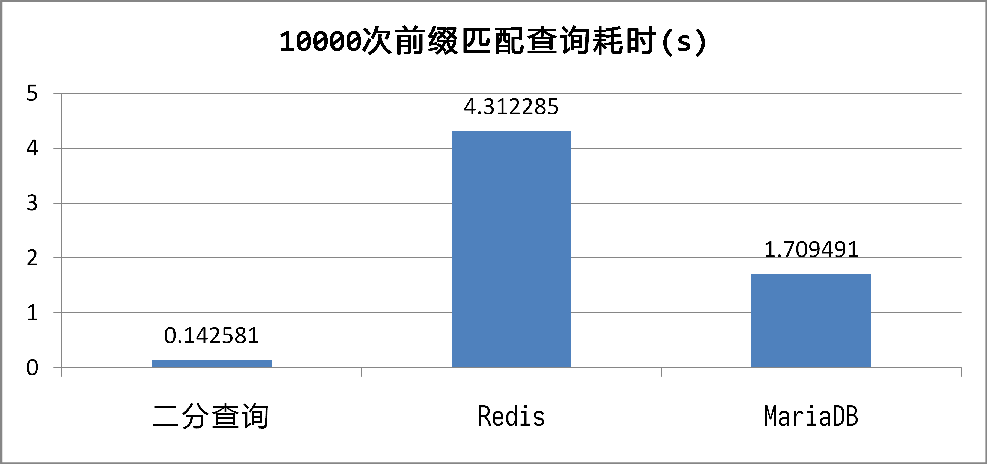
从耗时来看,O(n)的遍历查询妥妥垫底,O(log n)的二分查询秒杀全场,MariaDB的查询速度则远远甩开了Redis。当然,单次特定条件查询不能说明什么问题,下面来看看10000次随机前缀(长度为1~8的随机字符串)匹配查询所需要的时间:
不出所料,二分查询的速度是最快的,毕竟是在内存中以O(log n)的时间复杂度来查找数据。
MariaDB查找的速度比二分查找的速度慢上十倍,但性能依然出乎我的意料。InnoDB的B+树索引无疑是最大功臣,定位到特定前缀的首个UUID只需要O(log n)的时间复杂度,之后就只需要顺序读取数据。同时,100万个UUID的索引小到可以全部放入内存,这进一步提高了性能。
Redis这个以快著称的KV数据库反而最慢,但仔细想想也无可厚非。为了进行一次查询,我们需要执行如下操作:ZADD添加边界元素、ZRANK确定位置、ZRANGE提取结果、ZREM移除边界元素。而这些操作的时间复杂度都达到甚至超过了O(log n),速度当然快不起来。只能说《Redis实战》这本书提供了这样一个思路,但在具体实现上还是要更慎重。
后记 读完文章后可能会有读者大呼上当:100万的数据集也太小了吧?数据的插入和删除怎么解决?前缀树呢?好吧,这篇文章确实没有回答这些问题。直接在内存中进行二分查询性能确实非常好,但插入和删除数据的时间复杂度来到了O(n),同时也对超过内存容量限制的数据集无能为力。但是我觉得,前者可以通过分离数据的修改和查询解决(在数据库中修改,缓存到内存后查询),后者可以通过水平扩展解决(每个进程/机器缓存部分数据集),同时笔者水平有限,所以没有回答更深入的问题。
文章最后,衷心感谢黄健宏老师的著作《Redis设计与实现》和译作《Redis实战》。